

Tuning en MySQL

A medida que nuestras bases de datos y nuestro volumen de negocio va creciendo, es muy habitual empezar a apreciar un deterioro en el rendimiento de las mismas. Esto es lógico, ya que no se están soportando las mismas cargas de trabajo ni se está trabajando con el mismo volumen de datos que antes.
Ante esta situación, uno puede pensar que simplemente toca ampliar los recursos de los servidores y olvidarse de ello, pero lo cierto es que esta solución no siempre es ni necesaria ni idónea. En su lugar, se puede optar por “jugar” con los parámetros de configuración de MySQL con el fin de sacar un mejor rendimiento con los recursos que ya tenemos. Este proceso es el que se conoce como tuning.
Pero no es algo sencillo y requiere un análisis previo. Además, se debe tener mucho cuidado con lo que se hace, ya que podemos pasarnos de generosos e incrementar los valores hasta unos niveles que saturen nuestros servidores y afecten al servicio, o incluso modificar parámetros que no correspondan y acabar con un rendimiento peor que el que teníamos de inicio.
En este artículo vamos a ver algunos de los principales parámetros que se suelen modificar al hacer tuning y porqué.
¿Cómo puedo obtener métricas de mi base de datos?
Primero de todo, para analizar el estado actual de tus bases de datos y así determinar dónde están los puntos a mejorar, existen diferentes herramientas de monitorización y observabilidad que recogen información sobre diferentes aspectos de tu base de datos como uso del buffer, número de conexiones o deadlocks que se han producido, entre otros, teniendo un histórico para filtrar sobre los últimos días/semanas/meses o en un intervalo de fechas personalizado.
Una herramienta que nos resulta muy útil es Percona Monitoring and Management (PMM), cuyo agente cuenta con un exporter para MySQL.
Pero como decimos, no es la única herramienta existente y quizá ya estéis usando una perfectamente válida.
También podéis obtener diferentes datos y estadísticas a tiempo real con comandeo propio de MySQL, aunque no es la opción más ideal ya que solo ofrecerá los datos de ese momento concreto y no un histórico como el que podéis disponer al utilizar estas herramientas. No obstante, a lo largo del artículo dejaremos también los comandos que podéis usar para obtener cada tipo de información.
Parámetros habituales a modificar
Entramos ya en materia y os vamos a comentar algunos de los parámetros de MySQL que se suelen considerar y modificar cuando se quiere hacer tuning en bases de datos:
- innodb_buffer_pool_size: El buffer guarda en memoria los datos de tablas y sus índices, de tal modo, que cuando se vuelvan a requerir estos datos sean cargados desde la memoria y no desde el disco, ya que como sabemos la primera es mucho más rápida que el segundo. Obviamente, tener fijado el buffer a un valor alto es beneficioso ya que permitirá tener más datos guardados en memoria, pero a la vez es peligroso y se debe modificar este valor con mucho cuidado puesto que corremos el riesgo de llenar por completo la memoria física del servidor y que el OOM Killer nos mate el servicio. Si por ejemplo nuestro servidor de bases de datos tiene un total de 12 GB de memoria y fijamos este parámetro de innodb_buffer_pool_size a 8192m (8 GB), tenemos que estar muy seguros de que el resto de servicios de la máquina no van a consumir los 4 GB restantes para evitar problemas.
- innodb_buffer_pool_instances: Este parámetro determina el número de instancias o “regiones” en las que se divide el buffer antes comentado y admite un valor entre 1 y 64. Dividir el buffer en estas instancias o regiones ayuda a mejorar la concurrencia. En determinadas situaciones podemos encontrar cuellos de botella cuando múltiples hilos tratan de acceder simultáneamente al buffer, especialmente en bases de datos con un buffer grande y con muchos datos, y es aquí donde una mejora en la concurrencia puede ayudar enormemente. Siguiendo con el ejemplo anterior, si has fijado a 8 GB el parámetro innodb_buffer_pool_size, si fijas el innodb_buffer_pool_instances a 4, cada instancia o región cogerá 2 GB del buffer.
- thread_cache_size: Como quizá sepáis, en MySQL a cada nueva conexión se le asigna un hilo (thread) dedicado. Cuando un cliente se desconecta, el hilo es guardado en una caché para que pueda ser reutilizado por una nueva conexión reduciendo así el overhead de crear y destruir hilos constantemente. El máximo de hilos almacenados en caché se controla con este parámetro thread_cache_size. La clave aquí es el equilibrio. Un thread_cache_size bajo puede significar un overhead alto como ya hemos comentado, pero un valor alto en relación con el número de conexiones nuevas que se abren habitualmente en nuestra base de datos, puede resultar en un consumo de memoria innecesario para mantener más hilos de los necesarios en caché (en memoria), cuando esa memoria podría destinarse a otros fines. Por ejemplo, si observamos que incluso en las horas de mayor tráfico no solemos sobrepasar las 50 conexiones nuevas por minuto, de poco o nada nos servirá tener el valor thread_cache_size a 100, puesto que se estará desperdiciando memoria. Aquí es donde contar con una herramienta como PMM te puede ayudar enormemente a analizar tu caso concreto, ya que puedes ver fácilmente el histórico de conexiones a tu base de datos.
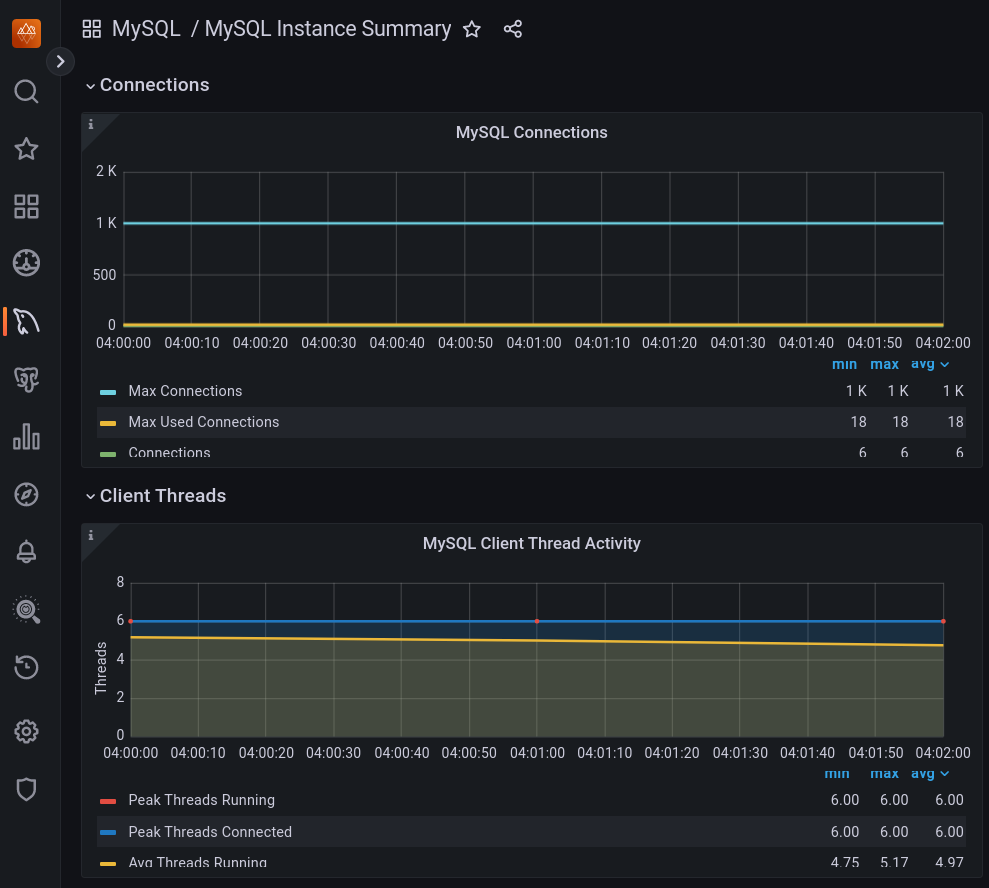
En caso de no disponer de herramientas, podéis emplear el comando show status where variable_name = 'threads_connected', pero como comentábamos al principio de este artículo, ya no estaréis viendo un histórico, sino las conexiones en ese momento dado:
- table_open_cache: Debido a la naturaleza multihilo y multitarea de MySQL, diferentes tablas pueden ser abiertas para su consulta simultáneamente. Para evitar que las tablas que más se consultan tengan que reabrirse constantemente, estas se mantienen en caché, y el número de tablas que se mantienen se controla con este parámetro. Para determinar a qué valor puedes fijar este parámetro, debéis comparar el número de tablas que suele haber abiertas con el tiempo que lleva el servidor en marcha. De nuevo, el histórico de número de tablas que suele haber abiertas se puede obtener fácilmente con herramientas de monitorización, o hacer uso de los comandos show global status like 'opened_tables' y show global status like 'uptime' respectivamente para ver los valores actuales. Se recomienda incrementar el valor de table_open_cache si observas que el número de tablas abiertas aumenta considerablemente en el tiempo.
- table_definition_cache: De manera similar a las tablas en sí, MySQL mantiene una caché de definiciones de tablas de modo que cuando se establece una nueva conexión, se puedan consultar rápidamente los metadatos de las tablas. Como norma general, no es mala idea tener este parámetro fijado al mismo número de tablas que existan en nuestra base de datos.
- innodb_io_capacity: Este es un parámetro que va de la mano con el tipo de disco del que disponga nuestro servidor. Básicamente, define la capacidad de InnoDB de realizar operaciones de entrada/salida (I/O) y es recomendable fijarlo en un valor similar a los IOPS del disco a fin de sacarle el máximo rendimiento. Hoy en día lo más habitual es trabajar con proveedores de nube y en ellos es muy fácil consultar este dato. Por ejemplo, en un volumen EBS de AWS:

De modo que, en este ejemplo, podríamos fijar el parámetro innodb_io_capacity en un valor que no sobrepase los 9500, y ¡ojo! recuerda dejar un margen medianamente prudente.
- innodb_io_capacity_max: InnoDB puede, en ocasiones donde la carga de trabajo aumenta, trabajar a un ratio de operaciones de entrada/salida por segundo (IOPS) mayor al definido en el parámetro innodb_io_capacity anteriormente comentado. Pero esto puede ser contraproducente y llegar a penalizarnos. Si queremos controlarlo, podemos utilizar este parámetro para limitar el máximo de IOPS en estas situaciones.
Esperamos que estas pinceladas os sean de utilidad a la hora de aventuraros a hacer tuning en vuestras bases de datos,
¡No faltéis a vuestra cita en próximos artículos ;)!