

Divide y vencerás: logstash pipelines

“¡Divide y vencerás!”. En informática lo conocemos como un algoritmo de resolución de problemas, pero es más que eso. Es una metodología basada en el principio de dividir un problema complejo de resolver (o irresoluble a priori), en pequeños problemas que sí son más sencillos y que la unión del resultado de éstos implica la resolución del problema original.
Esto mismo ocurre con los sistemas de centralizado de logs. Implica la configuración de múltiples sistemas y se puede complicar bastante cuando crecen tanto en número de componentes de diferentes tipos, como en el volumen de los datos a centralizar.
Además, hay datos que son necesarios recopilar en “tiempo real” en destino, otros no tanto. Puede haber muchos datos en un solo fichero o muchos datos distribuidos en miles de ficheros o sistemas de diferentes tipos, ya sea en un solo servidor o múltiples…etc. En consecuencia, una solución de implementación en un sistema puede no servir para otro; o incluso esta implementación en el mismo sistema con el paso del tiempo y de su propia evolución, puede no ser válida. Es de locos, pero es el día a día en sistemas.
Para ello, hoy te contamos cómo logstash también ha evolucionado y acude a nuestro rescate, para adaptarse a múltiples soluciones con su “navaja suiza”: los pipelines.
¿Qué es un Pipeline en Logstash?
Un pipeline es una implementación de configuraciones de logstash (input->filter->output) que puede ejecutarse de forma paralela o relacionada a otros pipelines distintos, y que se ejecutan con una misma instancia de logstash. Por defecto, logstash funciona como un único pipeline.
Muchos sistemas funcionarán durante años con esta configuración por defecto, sin necesidad de mayor complicación. De no ser así, cuando empiezan los problemas por la evolución lógica en complejidad y volumetría de datos, podremos utilizar distintos pipelines con la definición del fichero pipelines.yml. El formato del fichero es el siguiente:
- pipeline.id: pipeline1
path.config: "/ruta/a/configuracion/pipeline/pipeline01.conf"
pipeline.workers: 2
- pipeline.id: pipeline2
path.config: "/ruta/a/configuracion/pipeline/pipeline02.conf”
queue.type: persisted
- pipeline.id: pipeline3
path.config: "/ruta/a/configuracion/pipeline/pipeline03.conf”
[...]
Podemos modificar las configuraciones de funcionamiento de cada pipeline de forma independiente. Por defecto, cada pipeline hereda las configuraciones del pipeline principal por defecto, definido en el fichero logstash.yml.
Colas persistentes en pipelines
Por defecto, logstash utiliza colas implementadas en memoria (queue.type: memory) entre sus etapas (input -> pipeline workers) como buffer de eventos leídos de forma temporal. En el caso de ocurrir una parada inesperada del proceso, el contenido de esta memoria se perderá. El tamaño de esta memoria no puede definirse directamente, dependerá de las variables de configuración pipeline.batch.size y pipeline.workers.
Para poder evitarlo, logstash permite utilizar un sistema de colas persistentes en disco (queue.type: persisted), que almacenará los datos de la siguiente forma:
input → persistent queue → filter + output
Podemos definir diferentes parámetros de configuración de la cola según nuestras necesidades. De esta forma, podemos asegurar que si hay una parada inesperada del proceso de logstash, los eventos no se perderán y se retomará su lectura cuando se reanude. La desventaja es la pérdida de performance, que implica utilizar disco para la lectura/escritura de eventos, ya que al utilizar escrituras síncronas entre etapas, el pipeline verá penalizado su ratio de procesamiento.
Estas colas de retención nos permitirán además aliviar la congestión del procesamiento entre etapas de un pipeline. Si una cola persistente llega a su límite de capacidad, los procesos de entrada se detendrán hasta que baje su ocupación por debajo del límite.
Además nos sirve para poder identificar cuellos de botella en determinados flujos de datos definidos, y así poder abordar el análisis de su optimización de forma más precisa.
Contamos además con dos herramientas para ver el estado de la cola (pqcheck) o repararla (pqrepair) en caso necesario.
Comunicación entre pipelines
Una de las mayores ventajas de utilizar pipelines en logstash es la posibilidad de comunicar un pipeline con otro directamente. Vemos un ejemplo básico:
input_pipeline01.yml
input {
file {
path: “/un/path/a/fichero.txt”
}
}
output {
pipeline {
send_to => [“output_pipeline2”]
}
}
output_pipeline02.yml
input {
pipeline {
address => “output_pipeline2”
}
}
output {
elasticsearch {
[...]
}
}
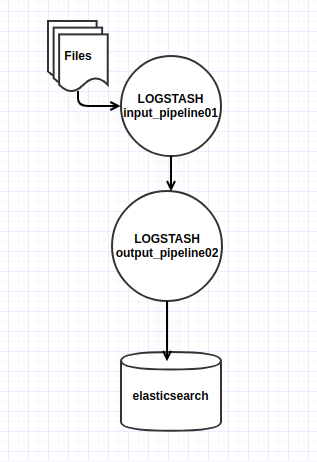
En el fichero input_pipeline01.yml se realiza la lectura de un fichero y se envían los datos al pipeline definido en output_pipeline02.yml a través de la dirección del input “pipeline { address”. De esta forma podemos desacoplar las configuraciones de lectura de datos con su salida, obteniendo diferentes ventajas. Algunas de ellas:
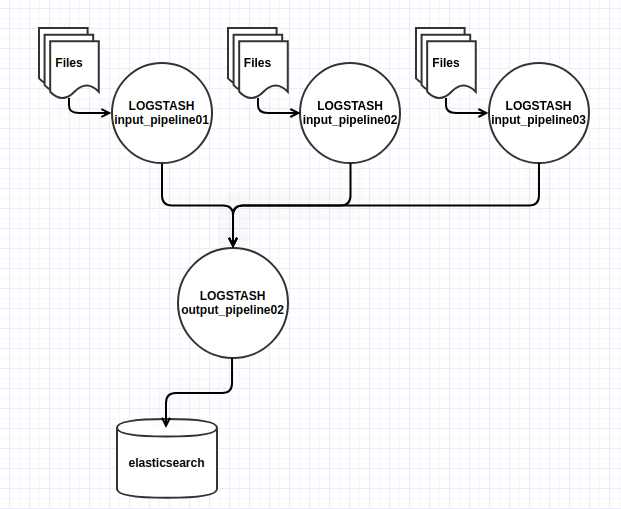
- Múltiples inputs: podemos utilizar múltiples pipelines de entrada (como pipeline01) con un mismo pipeline de salida (pipeline02), por lo que estaremos optimizando la lectura de forma paralela de varios orígenes de entrada diferentes y reutilizando el mismo pipeline de salida de datos.
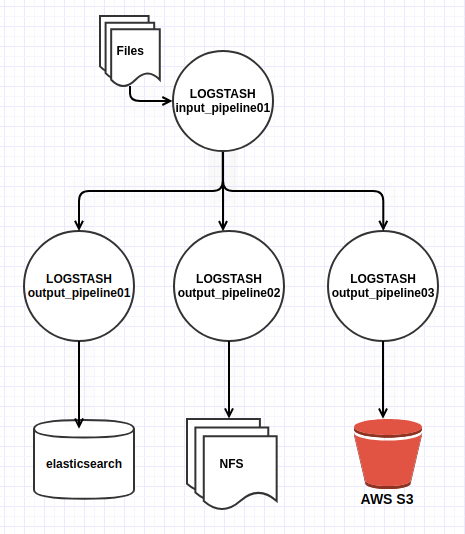
- Múltiples outputs: podemos utilizar múltiples pipelines de salida, de forma que un mismo evento de entrada pueda ser distribuido a varios destinos diferentes. Vemos un ejemplo:
input {
file {
path: “/un/path/a/fichero.txt”
}
}
output {
pipeline {
send_to => [“output_pipeline01”, “output_pipeline02”, “output_pipeline03”]
}
}
Es importante destacar que esta configuración no se comporta como un balanceo de carga ni a modo de “nodos de backup”, sino que los eventos serán enviados a cada uno de los pipelines. En el caso de que alguno de ellos no responda, el resto de ejecuciones no se detendrán, por lo que es una gran ventaja si tenemos varios outputs en serie en nuestras configuraciones de un único pipeline.
- Filtrado a modo de librería: por si no lo sabías, hasta la versión 8.15, logstash no permite hacer “includes” en el código que nos permitan reutilizar el mismo. No será que no ha sido reclamado por la comunidad. Una funcionalidad interesante, es utilizar un pipeline destinado a hacer tratamiento de los datos, que requieren bastantes líneas de código y en ocasiones ciertamente complejo. Este pipeline recibe los eventos de un tipo concreto para ser tratados antes de enviarlos a un pipeline de salida común. De esta forma no tendremos que repetir el mismo código y nos servirá a modo de librería. Un ejemplo:
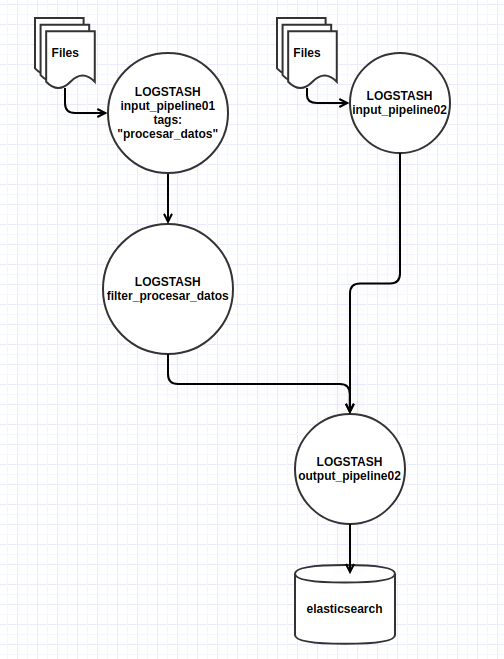
input_pipeline01.yml
input {
file {
path => “/un/path/a/fichero.txt”
tags => [“procesar_datos”]
}
}
output {
if “procesar_datos” in [tags]
pipeline { send_to => [“procesar_datos”] }
else pipeline { send_to => [“output_pipeline2”] }
}
filter_procesar_datos.yml
input {
pipeline {
address => “procesar_datos”
}
}
filter {
# procesado de datos
grok {
[...]
}
mutate {
[...]
}
}
output {
# salida al pipeline de elasticsearch
pipeline {
send_to => [“output_pipeline2”]
}
}
¿Usas pipelines en tus configuraciones de logstash? Si has llegado a leer hasta aquí y no los estás utilizando en tus implementaciones, estoy seguro que estos ejemplos te servirán de referencia.
A diario en STR Sistemas realizamos implantaciones de logstash de todo tipo. Hay tantas opciones como se te ocurra combinarlas. Cada sistema es un mundo diferente y requiere soluciones a medida para un uso óptimo de los recursos. En tu mano queda analizar tu caso de uso para maximizar las ventajas que te ofrecen. Siempre puedes contactarnos para ayudarte ;).
¡Ánimo y buena suerte!